The AI Stack ; APIs, Models, and Context Windows
How production AI systems are actually wired: API architecture, model selection, context management, cost/latency tradeoffs, and where attackers look first.
Every production AI system you will ever attack or defend has roughly the same shape. There is a front-end that takes user input, a backend that constructs a prompt, an API call to one or more model providers, optional middleware for retrieval and tools, and an output path back to the user or to downstream systems. The interesting failure modes do not live in any single layer. They live in the seams between layers, and that is where you focus.
The API layer in plain terms
There are two API shapes that matter. The older one is the completions API: you send a single string, you get a single string back. The modern one is the messages API: you send a list of role-tagged messages (system, user, assistant, tool), you get back an assistant message that may include tool use requests. Anthropic's Messages API, OpenAI's Chat Completions, and Google's GenerateContent all converge on this shape.
The flow looks like this:
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-5",
max_tokens=2048,
system="You are a security analyst. Be concise.",
messages=[
{"role": "user", "content": "Summarise CVE-2025-12345."},
],
)
print(response.content[0].text)Three operational details you have to know:
- Streaming versus blocking. A blocking call holds the connection open until the model finishes generating, which can be tens of seconds for long outputs. Streaming sends tokens as they are produced, which is the only acceptable UX for chat. Streaming also changes how you handle errors: a stream can fail mid-response after you have already shown content to the user.
- Token counting is server-side. You do not know exactly how many tokens your prompt consumes until the API tells you in the response. Estimate locally with the provider's tokenizer if you need to plan, but treat the server number as authoritative.
- Idempotency does not exist by default. Two identical calls produce two billable runs and potentially two different outputs. If you need at-most-once semantics, you build them yourself with deduplication keys upstream.
Model families and capability tiers
You will see a recurring three-tier pattern across providers: a frontier model, a mid-tier model, and a cheap fast model. Roughly:
| Tier | Anthropic | OpenAI | Use Case |
|---|---|---|---|
| Frontier | Opus | GPT-4.x | Complex reasoning, agents, hard tasks |
| Balanced | Sonnet | GPT-4o | Most production work, good price/quality |
| Fast | Haiku | GPT-4o-mini | Classification, routing, high-volume |
The right model is the cheapest one that solves your problem. Engineers default to the frontier tier and then complain about cost. The discipline is to start with the cheap model, measure where it fails, and only escalate where it matters. Most agent workflows benefit from mixed-tier: a fast model for routing and classification, a frontier model for hard sub-tasks.
Capability is not stable across versions. When a provider releases a new minor version, behaviour shifts. Prompts that worked perfectly on one snapshot may regress on the next. Pin your model version in production. Re-evaluate with your eval suite when you upgrade. If you do not have an eval suite, you have no way to detect a regression except by user complaints.
Context window management
You have a fixed budget of tokens per call. As conversations get longer or as retrieval pulls in more documents, you run out of space. There are three strategies, each with tradeoffs.
Naive truncation. Keep the last N messages. Simple, cheap, loses long-range memory. Acceptable for short transactional flows. Useless for anything that needs to remember earlier turns.
Sliding window with anchor. Keep the system prompt plus the last N messages. Slightly less terrible than pure truncation, still loses anything older than the window.
Summarisation. When the context approaches the limit, generate a summary of older messages with a cheap model, replace those messages with the summary, and continue. This preserves the gist of history at the cost of fidelity. It also introduces a new attack surface: the summarisation prompt sees user content and produces something the main model will trust as ground truth.
Production agents often layer summarisation with vector retrieval. The full history is stored externally, summarised in-context, and retrieved on demand when the agent needs specific facts. That is the architecture Module 3 covers in detail.
Cost and latency are coupled
A single API call has three latency components: time to first token (TTFT), per-token generation latency, and network round-trip. The first two scale with input and output length respectively. The third is your problem to optimise with regional routing and connection reuse.
For cost, you pay for input tokens and output tokens at different rates, with output usually three to five times more expensive than input. This has a counterintuitive consequence: a verbose prompt with a short output is much cheaper than a terse prompt with a long output. Prompt caching (Anthropic and OpenAI both offer it) further reduces the input cost for repeated prefixes, which is why a stable system prompt is worth its weight.
A useful mental model:
- Input tokens are cheap and high-volume. Spend them on context and instructions where it earns you correctness.
- Output tokens are expensive and slow. Constrain them. Short, structured outputs win.
- Latency budget is finite. A 200ms TTFT on a chat interface feels instant. A 2s TTFT feels broken.
Where attackers look first
Every AI system has the same five attack surfaces, and they are all on the seams.
1. The API key. This is the single most exploited vector in 2025. Keys end up in client-side JavaScript, in public GitHub repos, in mobile app binaries, in browser extensions, and in CI logs. Anyone with the key can run your model against your bill, exfiltrate your traffic, and (depending on permissions) modify your account. Never put a key in anything that ships to a client. Always proxy through your own backend with auth.
2. Rate limits. Most providers enforce both requests-per-minute and tokens-per-minute limits per organisation. An attacker who can trigger expensive model calls in your app (long context, max tokens) can DoS your AI features for everyone by exhausting the bucket. Per-user quotas and circuit breakers are not optional.
3. The prompt construction layer. This is where user input gets concatenated with system instructions, retrieved documents, and tool outputs into the final message list. Bugs here, like forgetting to escape, putting user content above the system message, or letting retrieved content contain instructions, are the root of most prompt injection findings.
4. Tool execution. When the model can call functions, the tool layer is where it interacts with the outside world. Every tool is a privilege the agent has on behalf of the user. Module 2 covers this in depth.
5. Model version drift. Providers retire and replace model snapshots on their own schedule. An evaluation that passed on claude-3-5-sonnet-20240620 may fail on claude-3-5-sonnet-20241022. If your prompt is fragile, a silent upgrade is a silent regression. Pin versions. Run continuous evals.
A concrete production architecture
A reasonable starting point for a backend that calls an LLM:
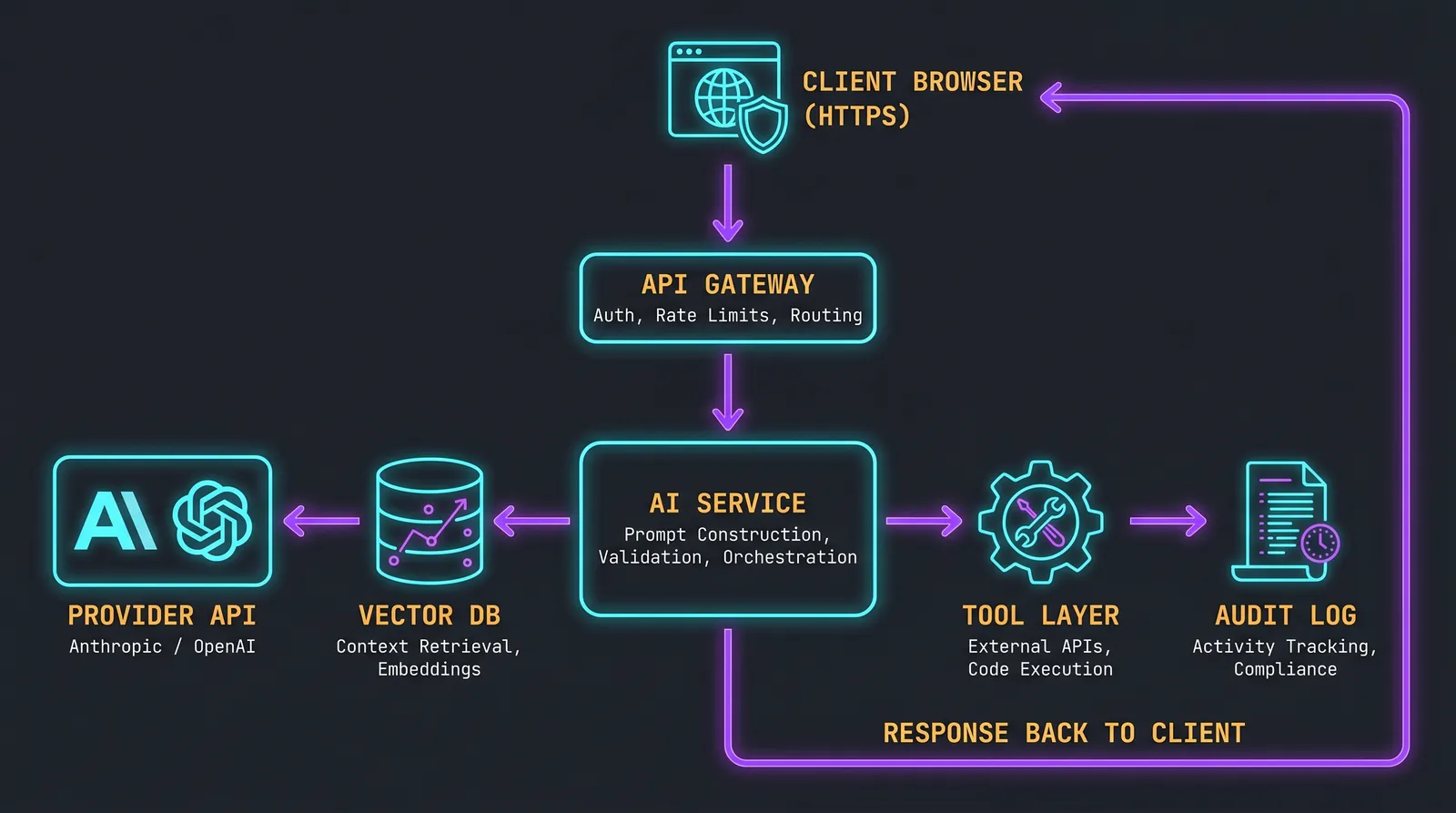
Two non-negotiable details. First, the audit log captures full prompt and full output, indexed by user, with retention tuned to your incident response window. Without this, you cannot investigate an attack after the fact. Second, the AI Service never trusts user input as instruction. User content goes into clearly delimited slots in the prompt structure. The model is told, in the system prompt, that anything in the user slot is data, not an instruction.
This is the stack. Every subsequent module assumes you understand the basic shape. When something goes wrong in production, the first question is always: which seam did it slip through.