How LLMs Work ; From Tokens to Reasoning
The engineering reality of transformer models, attention, tokenization, and why this matters for building and breaking AI systems.
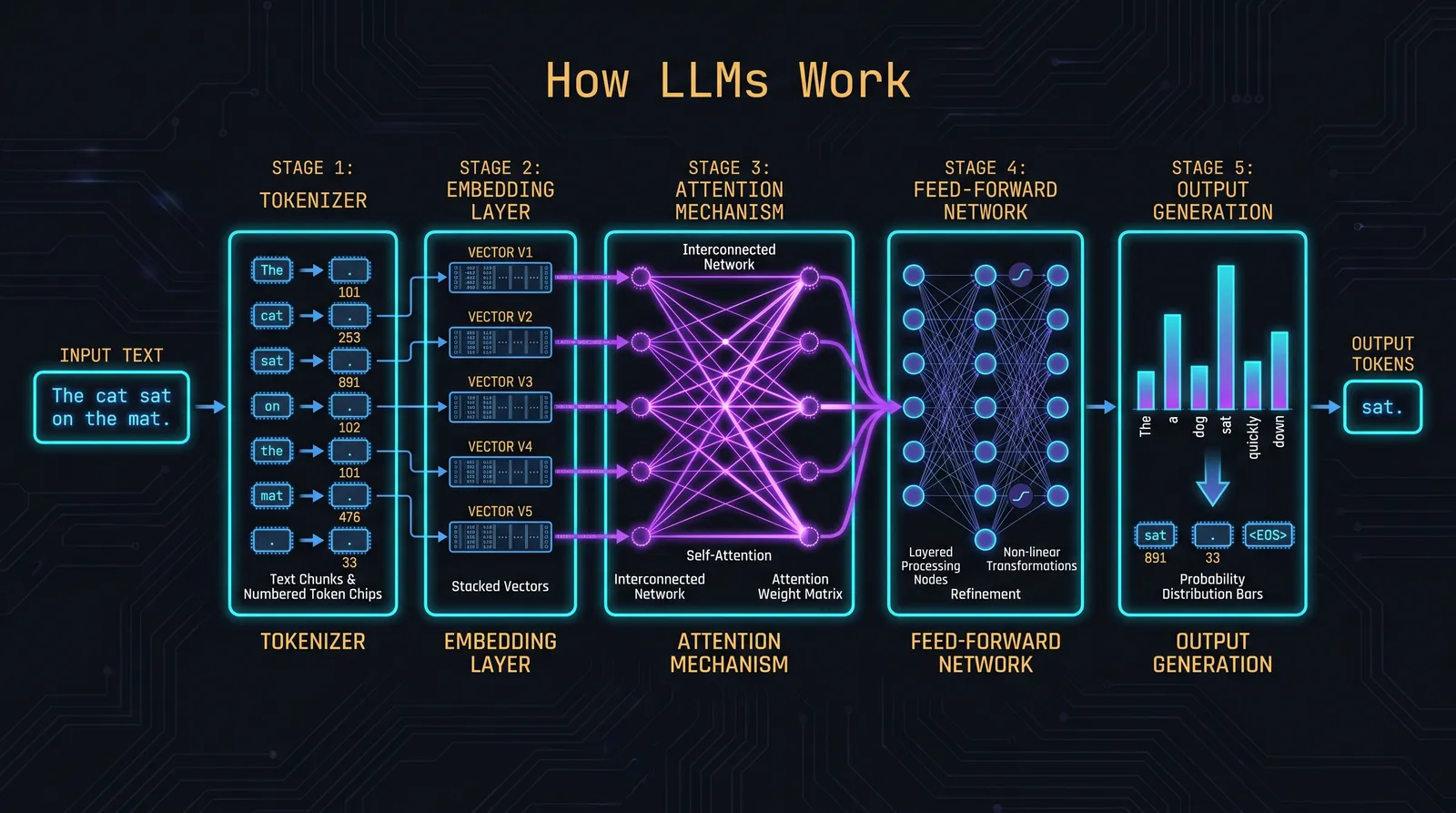
Most explanations of LLMs are either marketing fluff ("it predicts the next word") or research-paper math that buries the engineering reality. Neither is useful when you are trying to build or break one. The thing you actually need to internalize is mechanical: tokens go in, a probability distribution comes out, you sample from it, and the sample is appended to the input. The model then runs again with the longer input. That is the whole loop. Everything else ; system prompts, agents, tools, jailbreaks ; is built on top of that loop.
Tokens are not words
The model does not see characters or words. It sees integers from a fixed vocabulary, usually 50,000 to 200,000 entries, produced by a Byte-Pair Encoding (BPE) tokenizer. BPE starts with bytes and greedily merges the most common adjacent pairs until you hit a vocabulary size. Common English subwords win cheap encodings. Rare strings, code, punctuation runs, and non-Latin scripts get fragmented.
This produces effects that look like bugs and are actually fundamentals:
- The string
ChatGPTmay be one token, two tokens, or three depending on the tokenizer.chatgptlowercase often costs more tokens than the title-case version. - A SHA-256 hex digest is many tokens because hex digit runs are rare in training data.
- Tokenizer artifacts create capability cliffs. The infamous
SolidGoldMagikarpfailure on GPT-2 was a token that appeared in the vocabulary but barely in training data ; the model had no idea what it meant. - Spaces matter.
helloandhello(with leading space) are different tokens.
For security work this matters in two places. First, prompt length is measured in tokens, not characters, and the gap between the two is non-obvious. Second, byte-level smuggling attacks (homoglyphs, zero-width joiners, unusual Unicode normalization) often produce different token sequences than the visually identical legitimate input. That is an attack surface.
Attention is a weighted lookup, not magic
When the model processes a sequence, every token computes three vectors: a Query (Q), a Key (K), and a Value (V). For each position, the model takes the Query and dot-products it against every prior Key to score how relevant each prior token is. The scores get softmaxed into weights, then those weights mix the Values together. The result is a representation of "what does this position need to know from the rest of the sequence."
You can ignore the math. The useful intuition: attention is the mechanism that lets the model decide which earlier tokens matter for predicting what comes next. Multi-head attention runs that lookup in parallel with different learned projections, so different heads can specialize ; one for syntactic structure, one for entity tracking, one for coreference, and so on.
Two practical consequences:
- Attention is quadratic in sequence length. Doubling the context costs four times the compute. This is why context windows are a hard product constraint, not a free dial.
- Attention is a routing system. If you can get a token into the context, you can get the model to attend to it. That is exactly what prompt injection exploits.
Context windows are physical, not philosophical
A "200K context window" is not a knowledge cutoff or a memory in any human sense. It is the maximum number of tokens the model can process in a single forward pass. Everything outside that window does not exist to the model.
When building agents, the context window is your operating budget. You spend tokens on the system prompt, conversation history, tool definitions, tool results, retrieved documents, and the current user message. The model's actual usable attention degrades well before the window fills up ; there is a well-documented "lost in the middle" effect where information placed in the middle third of a long context is significantly less likely to influence the output than information at the beginning or end.
For attackers: the same effect means you can push a defender's safety instructions out of effective attention by stuffing the context with adversarial filler. This is the mechanism behind many-shot jailbreaks.
Sampling makes the model stochastic
The model's actual output is a probability distribution over the entire vocabulary for the next token. To pick one, you sample. The sampling parameters matter:
- Temperature scales the logits before softmax. Temperature 0 is deterministic (always pick the highest-probability token). Temperature 1.0 is the model's native distribution. Above 1.0 flattens the distribution toward uniform.
- Top-p (nucleus) keeps the smallest set of tokens whose cumulative probability exceeds p, then samples from that set.
- Top-k keeps the top k tokens and samples from them.
Temperature 0 is not safe. It is deterministic for identical inputs, but the input includes the entire prior context, and any change there reshuffles the distribution. Two near-identical user prompts can produce different outputs at temperature 0 if anything upstream differs by a single token.
This is the part that breaks traditional security testing. If a SQL injection payload bypasses a filter, it bypasses it every time. If a prompt injection payload bypasses safety training, it bypasses it sometimes. Testing AI systems requires running the same probe many times and reasoning about success rates, not booleans.
Base models vs RLHF-tuned models
The model that finished pretraining is called the base model. It is a next-token predictor over the entire training corpus. It will happily continue a paragraph of racist screed, complete a bomb-making manual, or roleplay as a malicious actor ; not because it wants to, but because that is what the next token of that pattern is.
To make it useful as an assistant, the base model goes through two more stages: supervised fine-tuning on instruction-following examples, then Reinforcement Learning from Human Feedback (RLHF) or Constitutional AI variants. These steps overlay a thin layer of "be helpful, harmless, honest" preference on top of the base capabilities.
The important property: this layer is thin. The base model's capabilities are still in there. Jailbreaks are mostly techniques for routing around the RLHF layer to access the base model's untrained behavior. This is why the same jailbreak that works on one provider often works on another ; the underlying mechanism is the same.
What this means for security engineers
Five things to carry forward:
- Hallucinations are an attack surface. A model will confidently emit false information that downstream code or humans then act on. Output validation is non-negotiable.
- Context window poisoning is real. Anything that ends up in the context ; retrieved documents, tool results, prior conversation ; has the same status as the user's instructions. The model cannot natively distinguish "trusted instruction" from "data being shown to it."
- Stochastic outputs break deterministic security tests. You need probabilistic evaluation: how often does the attack succeed across N runs?
- The safety layer is thin. RLHF is a polish, not a rewrite. Capabilities you would not want exposed are still in the weights.
- Token-level mechanics enable smuggling. Homoglyphs, unusual normalization, and tokenizer-edge encodings can bypass naive input filters while still being meaningful to the model.
Internalize the loop ; tokens in, distribution out, sample, append, repeat ; and the rest of the course is wiring on top of that primitive.