What Is an AI Agent ; The Loop, Memory, and Tools
The architectural reality of AI agents: the ReAct loop, tool use, memory layers, and why 'agent' means something specific and important.
"Agent" is currently the most over-used word in AI, and most of the time it means nothing more than "a chatbot with extra steps." That confusion is a problem because once you put real tools in a model's hands, the threat model changes completely. An agent is not a chatbot. An agent is software with three specific properties: it pursues a goal across multiple model calls, it uses tools to interact with systems outside itself, and it carries state between calls in some form of memory. That definition is mechanical and useful. If a system has all three, it is an agent and you should reason about it as one. If it lacks any of them, it is something simpler and the threat surface is smaller.
The ReAct loop is the entire architecture
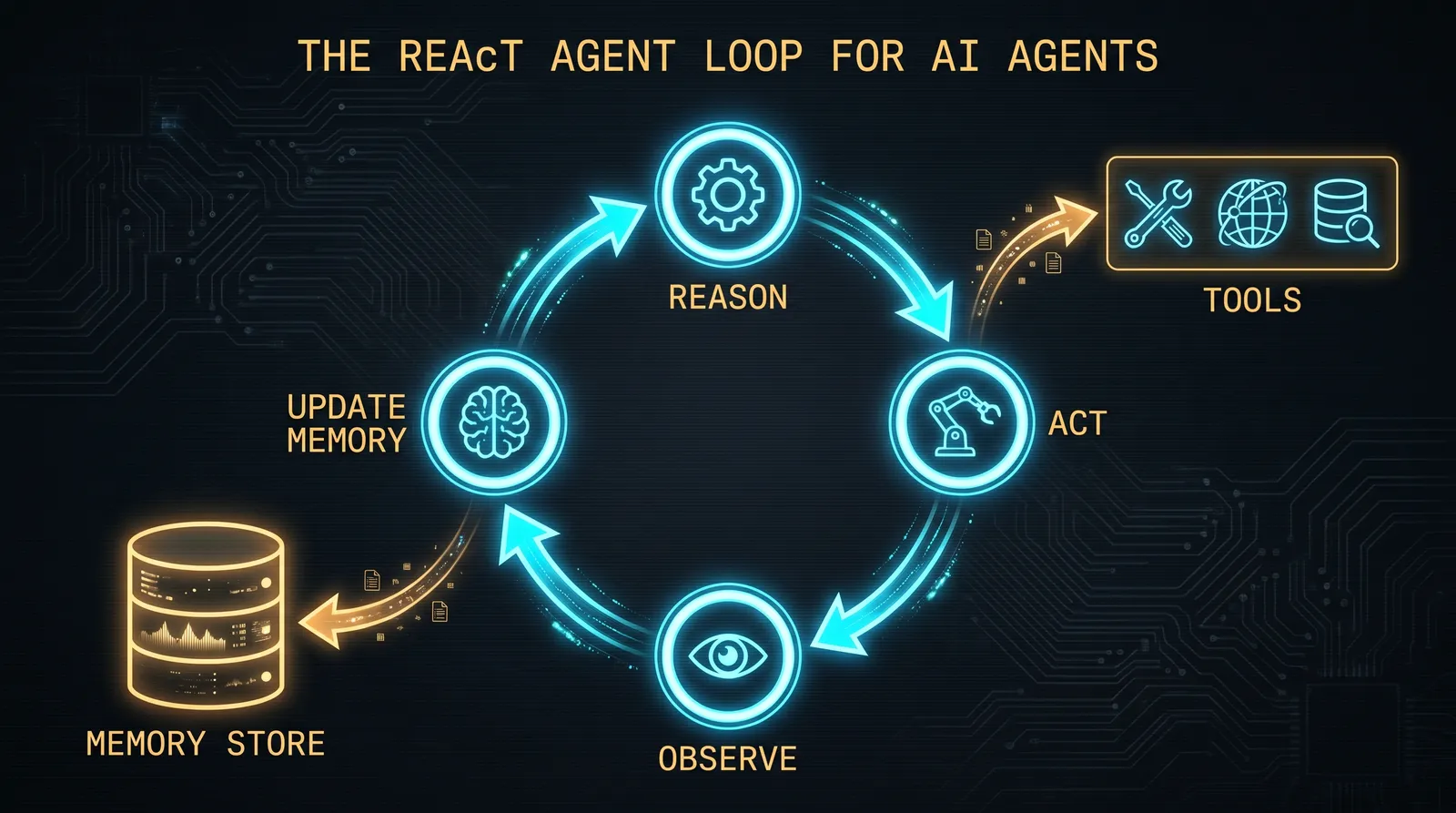
Every agent you will build or attack runs some variant of the same loop, popularised by the ReAct paper (Reason, Act, Observe). In pseudocode:
state = initial_state(goal, system_prompt)
while not done:
plan = model.generate(state) # reason
if plan.is_final_answer():
return plan.text
tool_call = plan.extract_tool_call() # act
result = execute(tool_call) # observe
state.append(plan, result)
if iteration > max_iterations:
break
Read that loop carefully. Five things are happening on every iteration. The model sees the current state. It produces output. That output either ends the loop with an answer or specifies a tool call. The tool call gets executed against the real world. The result gets appended to the state and the loop runs again.
Three observations that matter for both building and breaking agents:
-
The model never executes the tool itself. Your code does. The model emits a structured tool call. Your runtime parses it, validates it, runs the tool, and feeds the result back in. Every tool call is a privilege check opportunity, and most agents miss it.
-
The state grows on every iteration. Tool results get appended to the context. Long-running agents can blow past the context window if you do not summarise or prune. Production-grade loops have to manage this explicitly.
-
The loop terminates on the model's word. The model decides when it is done. If you do not bound the iterations, a confused or adversarial model can loop forever, burning tokens.
A chatbot does one model call per user message and then waits for the next one. An agent does many model calls per user message and acts on each one. That is the difference, and that is why agents are categorically more dangerous.
What makes an agent an agent
Three properties, all required:
Persistent goal. The agent has a higher-level objective that survives across multiple model calls. A chatbot is reactive: each turn is independent. An agent is goal-directed: it remembers what it is trying to accomplish and keeps working toward it. The goal can be set explicitly ("book me a flight to Tokyo") or implicitly (a coding agent's goal is the open task in your task list).
Tool use. The agent can take actions in the world: read files, query databases, call APIs, send messages, run code. Without tools, the model is just a text generator. With tools, the model is a small autonomous program that affects state outside itself. This is the property that turns "smart chatbot" into "potential threat actor."
Memory across calls. The agent retains something from one iteration to the next. At minimum, it retains the conversation so far. More advanced agents have layered memory: short-term working memory in the context, long-term key-value or vector storage across sessions, and episodic memory of past task executions. We will cover memory in detail in lesson 3.
If a system has all three, the threat model includes goal hijacking, tool abuse, and memory poisoning, plus all the threats from earlier modules. If it has none of them, you are dealing with a stateless text completion and the worst outcome is bad output. The risk model is fundamentally different.
Tool calling mechanics
Modern model APIs (Anthropic, OpenAI, Google) all support structured tool calling. You provide the model with a list of tool definitions in a JSON schema:
tools = [
{
"name": "search_web",
"description": "Search the public web. Returns a list of result objects with title, url, and snippet.",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Search query."},
"limit": {"type": "integer", "default": 5}
},
"required": ["query"]
}
}
]The model sees the tool name, description, and schema in its context. When it decides to call a tool, it emits a structured request:
{
"type": "tool_use",
"name": "search_web",
"input": {"query": "CVE-2025-12345 PoC", "limit": 3}
}Your runtime receives this, validates the parameters against the schema, executes the actual function, and sends the result back as a tool_result message. The model reads the result on the next iteration and decides what to do.
The tool description is the contract the model reads. If you write a vague description like "use this for searches," the model will call the tool wrong half the time. If you write a precise description like "search the company's internal documentation; do not use this for general web search; returns top 5 results sorted by recency," the model will use it correctly far more often. Tool descriptions are prompts. Treat them with the same care.
Memory in three layers
Production agents have memory at three layers, and each one has a different threat profile.
Working memory (in-context). The conversation history and tool results in the current context window. This is what the model can directly see and reason over. It is bounded by the context window and lost when the session ends unless you persist it externally.
Session memory (external key-value). A database keyed by session ID that stores facts the agent should remember within a session: the user's name, the task it is working on, intermediate results. The agent reads from this at the start of a turn and writes to it during the turn. Implementations range from a JSON blob in Postgres to a dedicated state store like Redis.
Long-term memory (semantic). A vector database that stores embeddings of past interactions, retrieved on demand by semantic similarity to the current query. This is how agents "remember" patterns across sessions. It is also where corpus poisoning attacks live.
For each layer, the writer matters. If an attacker can write to working memory (through injection), they influence one turn. If they can write to session memory (through a tool call), they influence the whole session. If they can write to long-term memory (by leaving content that gets ingested), they influence every future session that retrieves it. The blast radius grows with the layer.
Agent state management
A production agent is a state machine. It has roles, transitions, and termination conditions. A reasonable minimal state shape:
@dataclass
class AgentState:
goal: str
messages: list[Message]
tool_call_count: int
iteration: int
started_at: datetime
user_id: str
session_id: str
def is_terminated(self) -> bool:
if self.iteration >= MAX_ITERATIONS:
return True
if self.tool_call_count >= MAX_TOOL_CALLS:
return True
if (datetime.utcnow() - self.started_at).seconds > MAX_DURATION:
return True
return FalseThe state object answers three questions on every iteration: who is this agent acting for, what has happened so far, and is it allowed to keep going. The user_id is what lets you scope tool calls to the correct user's data. The iteration and tool call counters are what stop a runaway loop. The duration bound is what prevents a slow attack from burning your token budget all day.
Two patterns to adopt from the start. First, the agent's user_id is set once at session creation and is never editable by the model. The agent acts on behalf of that user only. Second, every tool call is logged with the full state: goal, iteration, parameters, result. Audit logs are how you investigate the inevitable "the agent did something weird" report.
Why agents change the threat model completely
A jailbroken chatbot says something embarrassing. A jailbroken agent sends emails on your behalf, transfers money, deletes files, leaks data to attacker-controlled endpoints, and propagates the compromise to every downstream system it touches. The capability gap between chatbot and agent is the same gap between "user submitted a bad form" and "user got remote code execution." That is not hyperbole. An agent with a run_shell tool and a successful injection is exactly remote code execution wearing a friendlier name.
Three properties of agents that compound the risk:
- Action capability. The agent does not just produce output. It does things. Tool calls are side effects on real systems.
- Trust inheritance. The agent acts with the privileges of whoever ran it. A successful injection inherits those privileges.
- Cross-system reach. A single agent often spans multiple systems: it reads from one, writes to another, summarises to a third. An injection in one source can propagate to all of them.
This is why every subsequent lesson in this course is more careful than the previous. Building a chatbot is straightforward. Building an agent safely is engineering with sharp edges. The next lesson walks through building one end to end so you can see those edges.