Your AI Agent Is Chaos. Tame It.
You will never make the model deterministic. So stop trying. You make the system around it deterministic, shrink the part that needs judgment to almost nothing, and put a fence around what's left. Here is how that actually works in code.

This is Part 3 of Agentic AI for Offensive Security, the foundations track of this blog. It runs alongside The Agentic Red Team, the hands-on build series where these concepts turn into running code. Part 1 named the animals. Part 2 explained why the dangerous one is dangerous. This one is about caging it.
People keep asking me how I make a nondeterministic model behave deterministically. The honest answer is that I don't, because I can't, and neither can anyone selling you a tool that claims to. The model is a demon. You don't argue a demon into predictability. You build a room it can't leave.
That reframe is the whole article. You do not make the model deterministic. You make the system around it deterministic, and you shrink the nondeterministic surface down to only the parts that genuinely need judgment. Then you put hard bounds on those parts. Everything else is plumbing, and plumbing is something engineers have known how to make reliable for fifty years.
Why can't you just make the model deterministic?
Because nondeterminism is the feature you're paying for.
The same property that lets an agent find an admin panel nobody told it about, the one from Part 1, is the property that makes its output impossible to predict line by line. Set the temperature to zero and you reduce the variance, you do not remove it. Floating point math, batching on the inference side, tiny changes in the prompt, all of it leaks variance back in. Two runs of the "same" agent against the "same" target will diverge. Plan for it.
So the goal was never determinism in the model. The goal is a system whose behavior you can reason about even though one component inside it gambles every time it speaks. That is a normal engineering problem. We wrap unreliable things in reliable structure constantly. A network is unreliable; TCP is not. A disk fails; RAID does not. The model is your unreliable component. Your job is the TCP around it.
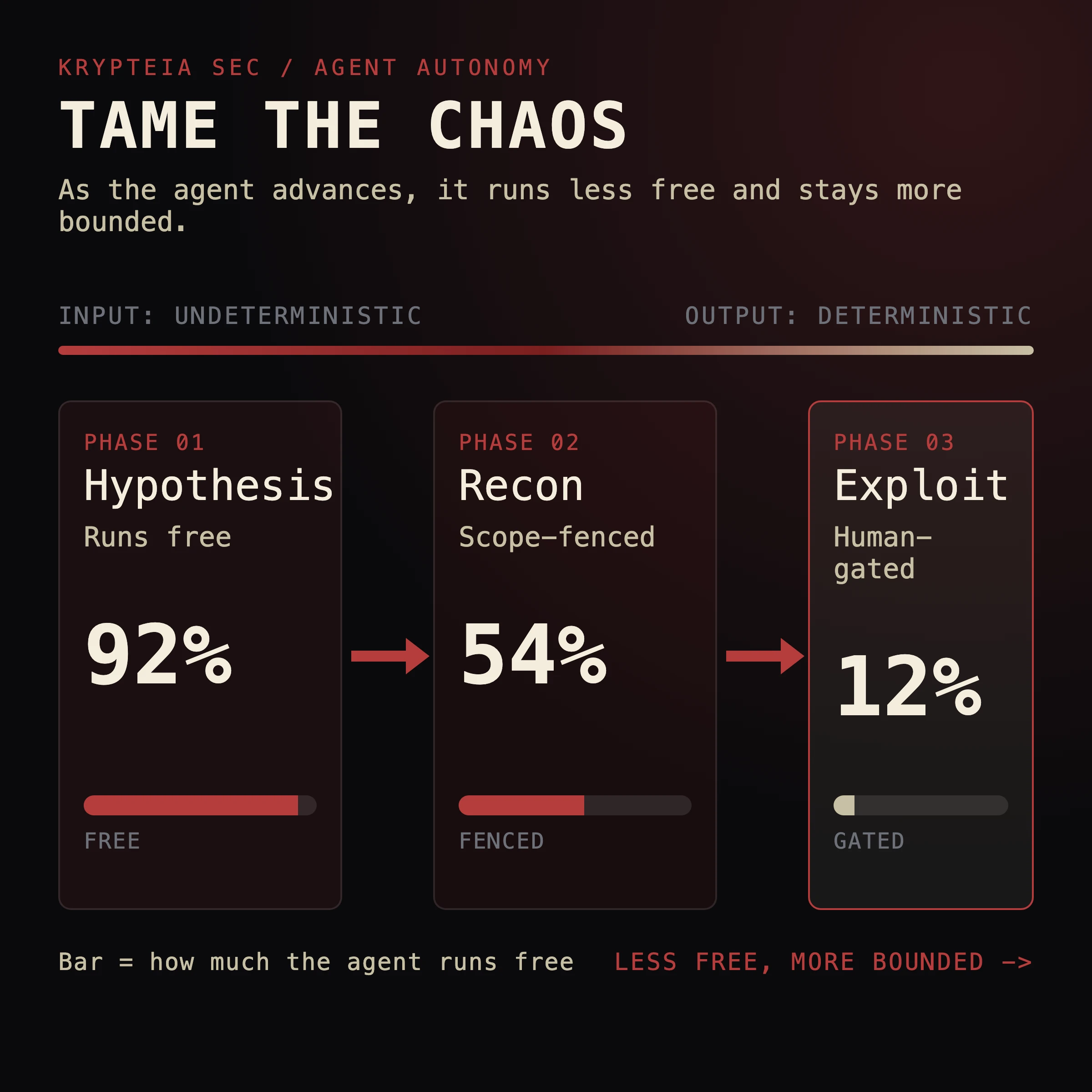
The determinism spectrum
Not every step an agent takes needs judgment. Most don't. The mistake I see in every junior agent build is treating the whole pipeline as one big creative act, when really it's a spectrum, and most of it should be nailed to the floor.
Mechanical recon sits at the near-deterministic end. Resolve a domain. Pull the DNS records. Request a known path. Parse a response into fields. There is exactly one correct way to do each of these, and a language model is the worst possible tool for them. You write these as plain code and call them like functions. The model never gets a vote on whether dig ran correctly.
Hypothesis generation sits at the irreducibly creative end. "Given what I just saw, what's worth attacking and how?" That is the demon's actual job. You cannot script it, because if you could script it you wouldn't need the agent. This is the narrow slice where nondeterminism earns its keep.
Firing an exploit sits at the human-gated end. This is the step with blast radius. Sending a payload that could take down a service, exfiltrating data, anything that touches a real system in a way you can't take back. The model can propose it. The model does not get to pull the trigger alone.
The skill is sorting every action your agent can take onto that line, then matching the control to the position. Deterministic steps get code. Creative steps get a bounded model call. High-blast-radius steps get a human. Most teams put the model in charge of all three and then act surprised.
How do you bound the creative part?
You constrain its inputs and you validate its outputs. The model gets to be creative inside a box, and you check everything that comes out of the box before anything downstream trusts it.
The first lever is structured output. Do not let the model return prose that you then parse with regex and hope. Make it return a schema, and reject anything that doesn't fit. A free-text answer is an attack surface and a parsing nightmare. A validated object is a contract.
import { z } from "zod";
// The model is allowed to be creative about WHICH hypothesis.
// It is not allowed to be creative about the SHAPE of its answer.
const ReconHypothesis = z.object({
target: z.string().url(),
technique: z.enum([
"path-discovery",
"auth-bypass",
"injection-probe",
"info-leak",
]),
rationale: z.string().min(10).max(500),
confidence: z.number().min(0).max(1),
// High blast radius? Then this had better be true,
// and a gate downstream is going to read it.
requiresApproval: z.boolean(),
});
type ReconHypothesis = z.infer<typeof ReconHypothesis>;
function parseHypothesis(raw: string): ReconHypothesis {
const json = JSON.parse(raw);
// Throws on anything off-contract. The model does not get
// to invent a technique we never wired a handler for.
return ReconHypothesis.parse(json);
}Notice what that schema does. It pins the technique to an enum, so the model cannot ask for an action you never built. It bounds the rationale length, so the model cannot smuggle a wall of text into a field you expected to be short. It forces a confidence number you can threshold on. And it makes the model state, up front, whether this thing needs a human. The creativity lives in the values. The structure does not move.
What do you do when validation fails?
You retry with the failure fed back in, and you cap the retries. This is the second lever, and it's where a lot of agent builds quietly fall apart.
When parse throws, you don't crash and you don't paper over it. You hand the model its own broken output and the validation error, and you ask again. Bounded. Three tries, then you stop and escalate, because a model that can't produce a valid object after three attempts is a model that's confused, and a confused agent firing at a target is exactly the failure mode you're trying to prevent.
async function getValidHypothesis(
prompt: string,
maxAttempts = 3,
): Promise<ReconHypothesis> {
let lastError = "";
for (let attempt = 1; attempt <= maxAttempts; attempt++) {
const raw = await callModel(
lastError
? `${prompt}\n\nYour last reply failed validation: ${lastError}\nReturn valid JSON matching the schema.`
: prompt,
);
try {
return parseHypothesis(raw);
} catch (err) {
lastError = err instanceof Error ? err.message : String(err);
}
}
// No infinite loop. No silent garbage. A loud, honest stop.
throw new Error(`Model failed to produce a valid hypothesis in ${maxAttempts} attempts`);
}The retry loop is deterministic structure wrapped around a nondeterministic call. The model is free to be wrong. The system is not free to act on wrong output, and it is not free to spin forever trying.
What's a control gate, and why name it?
A control gate is the chokepoint every action passes through before it's allowed to execute. It is the single place where you enforce scope, blast radius, and human approval. Name it, because a named gate is one you can audit, log, and reason about. An unnamed check scattered across forty functions is one you'll eventually forget to call.
Two things the gate enforces above all. First, a scope allowlist: the agent may only touch targets you explicitly authorized, and everything else is denied by default. An autonomous agent that can be talked into scanning an out-of-scope host through one poisoned response, the prompt injection risk from Part 2, is a liability with your name on the engagement letter. Deny by default. Allow on purpose.
Second, human approval on high blast radius. The model flagged requiresApproval. The gate reads it. If it's set, the agent stops and waits for a person.
const SCOPE_ALLOWLIST = new Set([
"https://lab.internal.example",
"https://gandalf.lakera.ai",
]);
type GateDecision =
| { allow: true }
| { allow: false; reason: string }
| { allow: false; reason: "needs-approval"; pending: ReconHypothesis };
function controlGate(h: ReconHypothesis): GateDecision {
const origin = new URL(h.target).origin;
// Scope first. Out of scope is never a judgment call.
if (!SCOPE_ALLOWLIST.has(origin)) {
return { allow: false, reason: `out of scope: ${origin}` };
}
// Confidence floor. Low-confidence guesses don't get to act.
if (h.confidence < 0.4) {
return { allow: false, reason: `confidence ${h.confidence} below floor` };
}
// Blast radius. The model proposes; the human disposes.
if (h.requiresApproval) {
return { allow: false, reason: "needs-approval", pending: h };
}
return { allow: true };
}Every action the agent wants to take goes through controlGate and nowhere else. The model's autonomy ends at that function. Inside the gate, nothing is creative. Scope is a set membership test. The confidence floor is a number comparison. The approval check is a boolean. All deterministic, all auditable, all the same on every run.
Where does this connect to the actual build?
This is the conceptual companion to the control-plane build over in The Agentic Red Team. That post wires these ideas into a running agent in Claude Code and walks it through jailbreaking Gandalf level by level. Read this one to understand why the control plane is shaped the way it is. Read that one to watch it work against a target that fights back.
The pattern there is the pattern here. Mechanical steps are code. The model gets one narrow, schema-bounded job: propose the next move. Every move it proposes passes through a named gate that checks scope, checks confidence, and routes anything with real blast radius to a human before a single packet leaves the machine. The demon does the thinking. The room does the containing.
The thing to actually take away
Stop trying to tame the model. It is not tamable and it is not supposed to be, because the wildness is the value. Tame the system.
Sort every action onto the determinism spectrum. Code for the mechanical, a bounded and validated model call for the genuinely creative, a human for anything with blast radius. Force structured output and reject what's off-contract. Retry with the error fed back, capped, then stop loud. Funnel every action through one named gate that denies out-of-scope by default and holds the trigger on anything irreversible until a person says go.
Do that and your agent stops being a demon you're praying about and becomes a demon you're employing. Same power. A room it can't leave. That is the whole game, and it's the difference between a tool you can put on a real engagement and a science project that scans the wrong host at two in the morning with your name on the contract.
Next in this track we shift from caging the agent to using it as a weapon: a working taxonomy of how you actually hack AI. Everything lands at krypteiasec.com first.